"Captioning dialogue is one thing. But captioning sound is another."
— Christine Sun Kim
Presented at the 2021 Designing for Accessibility Project Fair at Stanford University.
Whether it's a tender moment in a rom-com movie or a jump scare in a horror film, sound plays an integral role in a viewer's experience. Even beyond the soundtrack of a movie are other details like background music and environmental sounds which provide context and emotion that may go unnoticed to those who can’t hear that information. SoundSight is a visualization engine to create better representations of such sounds in video content for Deaf and Hard of Hearing users.
Developed with Lloyd May.
While closed captioning is great for encapsulating dialogue in a video, it doesn't capture everything. After interviewing a number of people who are Deaf or Hard of Hearing, we found that semantic and emotive information which informs video content can often get lost in closed captioning. As Christine Sun Kim explains, a mournful violin playing in the background of a scene can often get reduced to something like “[music],” lacking emotional and informative depth ("Artist Christine Sun Kim Rewrites Closed Captions").
"Captioning dialogue is one thing. But captioning sound is another."
— Christine Sun Kim
We wondered — how might we create a better way to capture the musical and emotional experience of watching visual content?
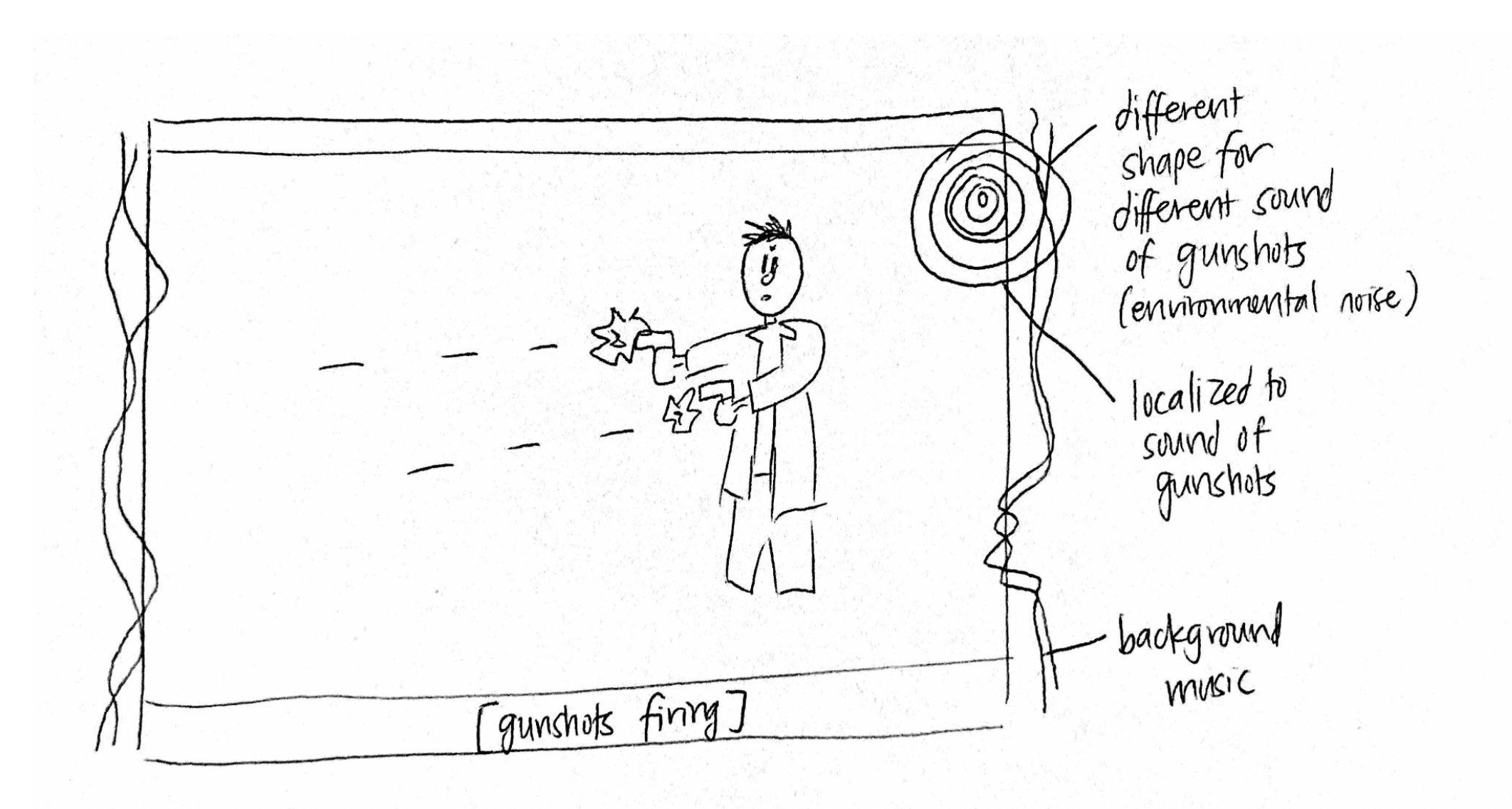
Using the insights we gathered from our needfinding interviews, we developed the idea of creating a sound visualizer which maps different sonic parameters to visual parameters. These visualizations would capture sounds like music and environmental noises which aren't typically conveyed by closed captioning and would overlay on the video to supplement (not replace) closed captions.
To better understand which of these variables might prove helpful or prove too distracting, we conducted 2 rounds of prototyping and user-testing with both Deaf and Hard of Hearing users.
To conduct these user tests, we created 3 different visualizers for 3 different movie clips. Participants were asked to watch each clip and then respond to a few qualitative questions measuring clarity, understanding, aesthetics, and level of distraction for each clip.
After these rounds of user-testing, we identified the following insights to inform revisions for future prototypes.

Spacialized sound seemed appealing. We were able to validate our assumption that placing the visualizer on the side of the screen where the sound originated would add helpful context to the viewing experience. Multiple participants expressed interest in spacialized sound and understood that it was conveying location.

Voice visualizer was redundant. One of our prototypes included a scene where our protagonist gives a long and emotional speech, so we built separate visualizers for both the background music and for the speaker’s voice. Users found this distinct voice visualizer distracting, as the closed captions were already there. They expressed preference to watching the speaker’s mouth and facial expressions instead.
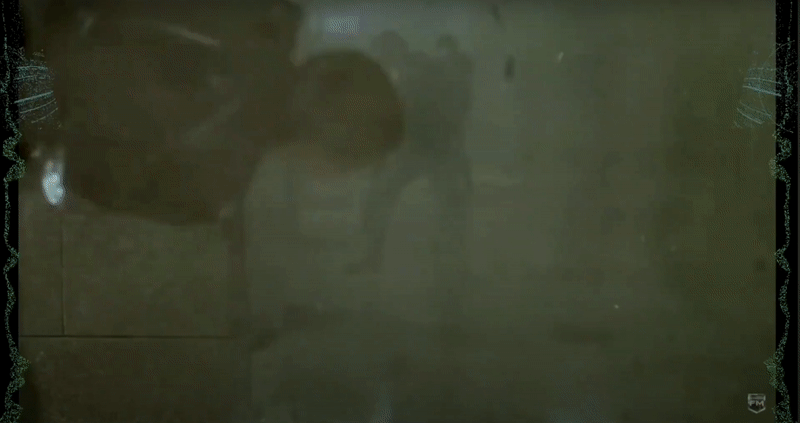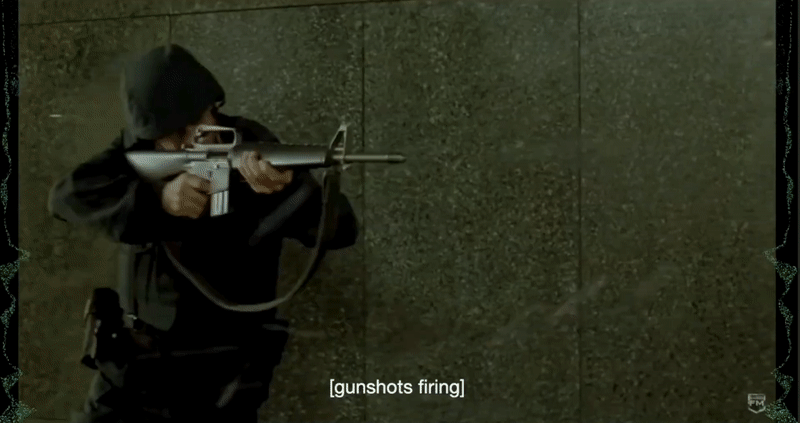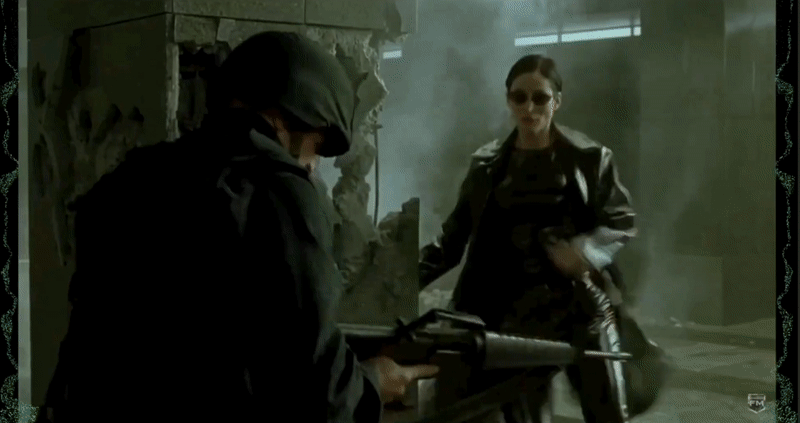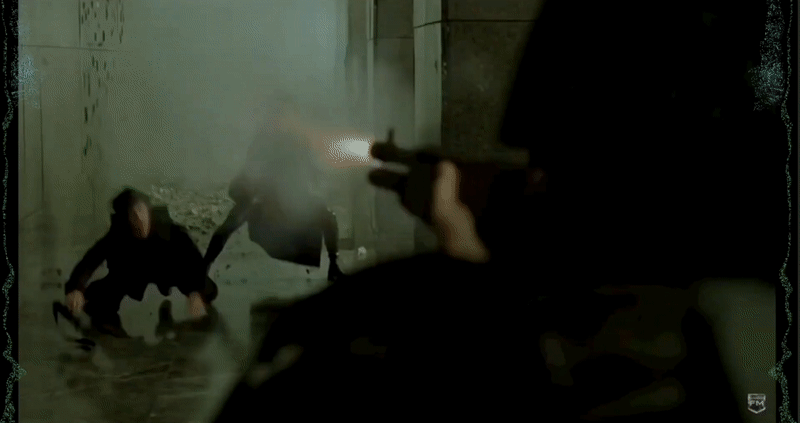
Screen position of the visualizer relative to the closed captioning. Our design originally placed the visualizations on the left and right of the screen; however, some users noted that they would have to look the entire length of the screen East-West “like a lizard” in order to get a sense of what sounds they were conveying.
Given the limited scope of our user-testing, next steps include conducting more widely-tested surveys with more controlled and finer-tuned visualization prototypes. We'd also like to explore the option of leaving more room for aesthetic customization with regard to color, thickness, screen position, etc.